Process data with a cloud system
In this tutorial, we will use a cloud system build on AWS, to process data. The objective is to store a dataset into a S3 cluster, to clean and store the data to a NoSQL database, Cassandra, and to query it. The cloud system is composed of a cluster in which we have installed Spark and Cassandra. Refers to this other aticle on the blog to see the design and the deploiement of the system.
We will use the Global Database of Events, Language, and Tone (GDELT). This database gathers news from around the world, as described on their website:
The GDELT Project monitors the world’s broadcast, print, and web news from nearly every corner of every country in over 100 languages and identifies the people, locations, organizations, themes, sources, emotions, counts, quotes, images and events driving our global society every second of every day, creating a free open platform for computing on the entire world.
The workflow to process the data is divided in 3 parts: get the data and store it to S3, clean the data and store it on Cassandra, then query it according to our needs.
The code is written in Scala, to interact with Spark. The code is divided into 3 Zeppelin notebook. For the complete code, refers to the dedicated folder on the GitHub repo of the project.
This project was part of a NoSQL course at Télécom Paris. It was to be done in teams of 4. The constraints were to deploy a cluster with a database allowing a distributed, resilient and efficient storage system, to be able to process 800 GB of data.
I- Get the dataset and store it into a S3 bucket
First, we have to download the data from the GDELT platform, to store it into a S3 bucket. We will load one month of data.
First, we write a function to download a file identified by its url. We use this function to download the masterfilelist, containing the complete list of the files composing the GDELT database.
import sys.process._
import java.io.File
import java.net.{URL, HttpURLConnection}
import org.apache.spark.sql.{functions._, SQLContext}
def fileDownloader(urlOfFileToDownload: String, fileName: String) = {
val url = new URL(urlOfFileToDownload)
val connection = url.openConnection().asInstanceOf[HttpURLConnection]
connection.setConnectTimeout(5000)
connection.setReadTimeout(5000)
connection.connect()
if (connection.getResponseCode >= 400)
println("error")
else
url #> new File(fileName) !!
}
fileDownloader("http://data.gdeltproject.org/gdeltv2/masterfilelist.txt", "/home/ubuntu/data/masterfilelist.txt")
Then, we store the master file into the S3 bucket gdelt-bucket:
import com.amazonaws.services.s3.AmazonS3ClientBuilder
import com.amazonaws.services.s3.AmazonS3
@transient val awsClient = AmazonS3ClientBuilder.standard().withRegion("us-east-1").build();
awsClient.putObject("gdelt-bucket", "masterfilelist.txt", new File( "/home/ubuntu/data/masterfilelist.txt"))
We read the masterfile and store its content to a dataframe:
import org.apache.hadoop.fs.s3a.S3AFileSystem
val sqlContext = new SQLContext(sc)
val masterFileDF = sqlContext.read.
option("delimiter"," ").
option("infer_schema","true").
csv("s3a://gdelt-bucket/masterfilelist.txt").
withColumnRenamed("_c0","size").
withColumnRenamed("_c1","hash").
withColumnRenamed("_c2","url")
masterFileTranslationDF.show(false)
+-------+--------------------------------+--------------------------------------------------------------------------------+
|size |hash |url |
+-------+--------------------------------+--------------------------------------------------------------------------------+
|49305 |18f9b16f0bc6b1e203b963264b7c90f1|http://data.gdeltproject.org/gdeltv2/20150218224500.translation.export.CSV.zip |
|133082 |d019304ace29aec800f688b616fceb06|http://data.gdeltproject.org/gdeltv2/20150218224500.translation.mentions.CSV.zip|
|9117874|fb4bb6d180eb8cde5825a8e6dbab1865|http://data.gdeltproject.org/gdeltv2/20150218224500.translation.gkg.csv.zip |
|59173 |b634baabd40fbe078f723829e7e4639f|http://data.gdeltproject.org/gdeltv2/20150218230000.translation.export.CSV.zip |
|151173 |19921c77b5d898f313ded534fdc1cd61|http://data.gdeltproject.org/gdeltv2/20150218230000.translation.mentions.CSV.zip|
+-------+--------------------------------+--------------------------------------------------------------------------------+
We filter the dataframe to only keep the files from December 2019. We then download those files locally, with the fileDownloader() function, and then we upload the files to the S3 bucket.
import com.amazonaws.services.s3.AmazonS3Client
val sampleDF = masterFileAllDF.filter($"url" rlike "201912[0-9]*").cache
object AwsClient{
val s3 = new AmazonS3Client()
}
sampleDF.select("url").repartition(100).foreach( r=> {
val URL = r.getAs[String](0)
val fileName = r.getAs[String](0).split("/").last
val dir = "/home/ubuntu/data/"
val localFileName = dir + fileName
fileDownloader(URL, localFileName)
println(URL)
val localFile = new File(localFileName)
AwsClient.s3.putObject("gdelt-bucket/data", fileName, localFile)
localFile.delete()
})
II- Prepare the data and store it into Cassandra tables
The objective of the data processing will be to prepare a table that we will query, to answer this question:
Map the relationships between countries according to the tone of the articles: for each pair (country1, country2), calculate the number of articles, the average tone (aggregations on Year / Month / Day, filtering by country or square of contact information).
We load the data from S3 to a Spark RDD. We select the useful csv, all finishing by exports.csv, which are the csv containing the data about the GDELT events:
// Load the data in a RDD
val eventsRDD = sc.binaryFiles("s3a://gdelt-bucket/data/201912[0-9]*.export.CSV.zip").
flatMap { // unzip the files
case (name: String, content: PortableDataStream) =>
val zis = new ZipInputStream(content.open)
Stream.continually(zis.getNextEntry).
takeWhile{ case null => zis.close(); false
case _ => true }.
flatMap { _ =>
val br = new BufferedReader(new InputStreamReader(zis))
Stream.continually(br.readLine()).takeWhile(_ != null)
}
}
Then we convert the RDD into a dataframe and select the necessary columns:
// Convert the RDD into a dataframe
val arrays = eventsRDD.map(_.split("\t"))
val maxCols = arrays.first().length
val eventsDF = arrays.toDF("arr")
.select((0 until maxCols).map(i => $"arr"(i).as(s"col_$i")): _*)
// Select the necessary columns
val newNames = Seq("globaleventid", "sqldate", "actiongeo_countrycode", "actor1countrycode", "actor2countrycode", "numarticles", "avgtone")
val eventsDF_R4 = eventsDF.select("col_0", "col_1", "col_53", "col_7", "col_17", "col_33", "col_34").toDF(newNames: _*)
eventsDF_R4.show()
To finish the data preparation, we add two columns, to get the month and the year of the events:
val eventsDF_R4_cleaned = eventsDF_R4.withColumn("monthyear", compute_month_udf($"sqldate")).withColumn("year", compute_year_udf($"sqldate"))
println(eventsDF_R4_cleaned.count())
eventsDF_R4_cleaned.show()
+-------------+--------+---------------------+-----------------+-----------------+-----------+-----------------+---------+----+
|globaleventid| sqldate|actiongeo_countrycode|actor1countrycode|actor2countrycode|numarticles| avgtone|monthyear|year|
+-------------+--------+---------------------+-----------------+-----------------+-----------+-----------------+---------+----+
| 890018526|20181201| UK| | GBR| 2|-8.74587458745875| 201812|2018|
| 890018527|20181201| UK| | | 6|-2.80898876404495| 201812|2018|
| 890018528|20181201| UK| | GBR| 4|-2.80898876404495| 201812|2018|
| 890018529|20181201| PK| GBR| PAK| 4|-7.36775818639798| 201812|2018|
| 890018530|20181201| AF| GBR| PAK| 4|-7.36775818639798| 201812|2018|
+-------------+--------+---------------------+-----------------+-----------------+-----------+-----------------+---------+----+
We now store the data into a Cassandra table, r4:
eventsDF_R4_cleaned.write
.cassandraFormat("r4", "gdelt_space")
.mode("overwrite")
.option("confirm.truncate","true")
.save()
The table has previously been created into Cassandra, with this command:
CREATE TABLE r4 (globaleventid text, sqldate text, actiongeo_countrycode text, actor1countrycode text, actor2countrycode text, numarticles text, avgtone text, monthyear text, year text, PRIMARY KEY (globaleventid));
III- Query the database
We will now query the table r4 to answer the question. There are particularly two possibilities to do so:
- query the table with the Cassandra Query Language (CQL). This is the most optimized way.
- load back the table into a dataframe and then manipulate it with classical means (data processing via a Spark dataframe, querying via Spark SQL, etc.). We implemented this way of doing, for practicality.
val result_r4 = spark.read.cassandraFormat("r4", "gdelt_space").load()
result_r4.createOrReplaceTempView("r4")
result_r4.show()
+-------------+---------------------+-----------------+-----------------+-----------------+---------+-----------+--------+----+
|globaleventid|actiongeo_countrycode|actor1countrycode|actor2countrycode| avgtone|monthyear|numarticles| sqldate|year|
+-------------+---------------------+-----------------+-----------------+-----------------+---------+-----------+--------+----+
| 893060950| PK| | | 1.09389243391066| 201912| 3|20191215|2019|
| 891228565| GM| | DEU|-1.52582159624414| 201912| 8|20191206|2019|
| 895594962| SP| | |-2.51572327044025| 201912| 10|20191229|2019|
| 893321359| US| USA| |-5.08326029798422| 201912| 1|20191216|2019|
| 892548565| UK| | GBR| 0.35650623885918| 201912| 6|20191212|2019|
+-------------+---------------------+-----------------+-----------------+-----------------+---------+-----------+--------+----+
We then perform the query with Spark SQL, and display the result with a Zeppelin library:
z.show(spark.sql(""" SELECT actor1countrycode, actor2countrycode, sqldate, SUM(numarticles) AS count_articles, AVG(avgtone) AS avg_tone FROM r4 WHERE actor1countrycode == "FRA" AND actor2countrycode == "ARG" GROUP BY actor1countrycode,actor2countrycode,sqldate ORDER BY sqldate LIMIT 100 """))
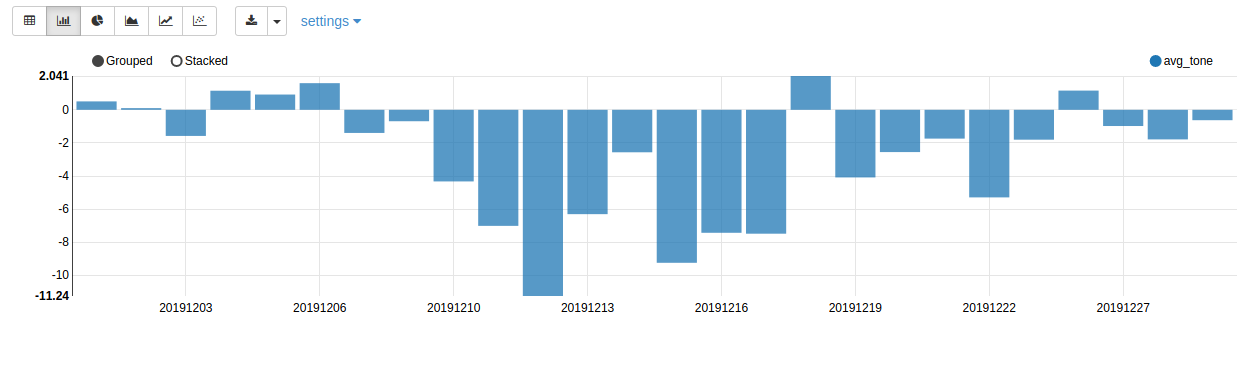
The resulting graph
The graph shows the evolution of the average tones of the articles written by France media, about Argentina, during the month of December 2019. The tone became negative after December 10, the day of the election of the new president, Alberto Fernández.
Refers to the GitHub repository of the project to see more requests and visualization.
Conclusion
This project let us manipulate data through a distributed cloud system. We divided the process, from data loading to query, into three parts, each with a corresponding notebook.
This project showed us how it is convenient to use a cloud system once the infrastructure is deployed.
To finish, the GDELT database appears to present a lot of analysis possibilities.
You can see the complete code and project explanations on the GitHub repository of the project.
Illustration photo by Susanne Jutzeler, suju-foto from Pixabay
